创建集群
- redis的安装包中包含了redis-trib.rb,用于创建集群
- 接下来的操作在192.168.12.107机器上进行
- 将命令复制,这样可以在任何目录下调用此命令
sudo cp /usr/share/doc/redis-tools/examples/redis-trib.rb /usr/local/bin/
- 安装ruby环境,因为redis-trib.rb是用ruby开发的
sudo apt-get install ruby

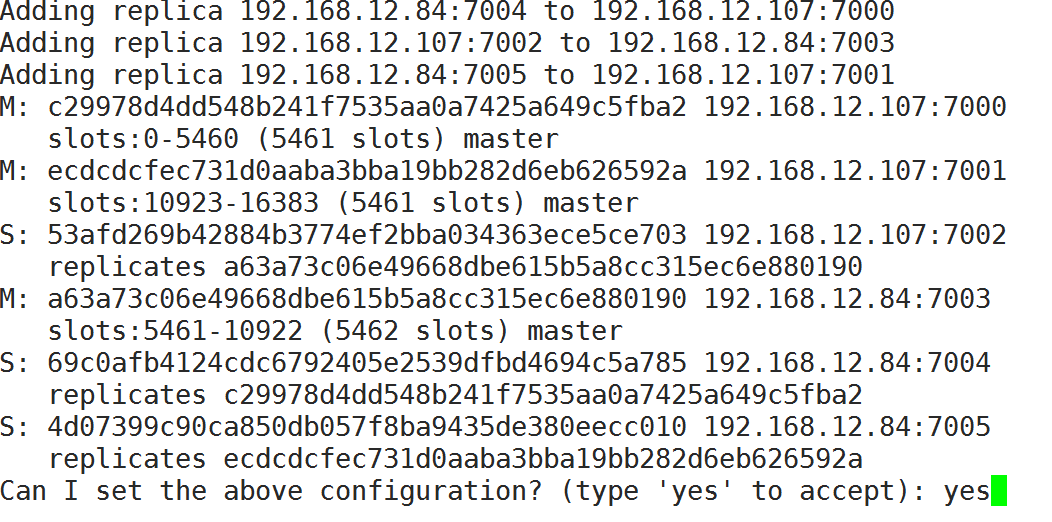
redis-trib.rb create --replicas 1 192.168.12.107:7000 192.168.12.107:7001 192.168.12.107:7002 192.168.12.84:7003 192.168.12.84:7004 192.168.12.84:7005
数据验证
- 根据上图可以看出,当前搭建的主服务器为7000、7001、7003,对应的从服务器是7004、7005、7002
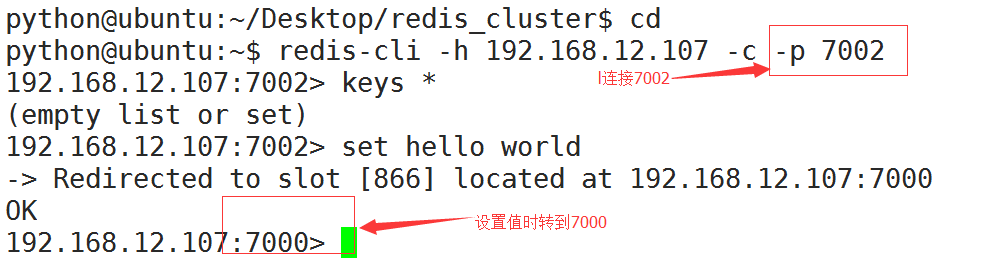
- 在192.168.12.107机器上连接7002,加参数-c表示连接到集群
redis-cli -h 192.168.12.107 -c -p 7002
set hello world
- 7000对应的从服务器为7004,所以在192.168.12.84服务器连接7004,查看数据如下图

- 在192.168.12.84服务器连接7005是没有数据的

在哪个服务器上写数据:CRC16
- redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据
- Redis集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了7000端口的节点
- Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master
- 需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了